August 2, 2021
15
min read
LDA and the method of topic modeling
In order to generate useful recommendations, we need to train it on not only text, but some context about that text...

In order to generate useful recommendations, we need to train it on not only text, but some context about that text...
In our previous blog we mentioned the need for Topic Modeling. One common application is an email filter. You train the model by feeding it many emails, each one labeled as “spam” or “urgent” or “work-related” or “promotion” or “social.”
(meaning it’s not spam). When a new email arrives, you use this trained model to infer whether it’s spam or not.
Next you give it a new email, use the model to infer whether it’s spam or not.
In order to generate useful recommendations, we need to train it on not only text, but some context about that text. For example, "do I need an umbrella tomorrow?" is about weather. But it's also about the calendar, and a little bit about fashion (I prefer a raincoat with a hat). So we need to build a model to define some topics (weather, calendar, fashion, politics, sports, economics, etc.) and then use that model to detect those topics in a new sentence (weather=0.8, calendar=0.15, fashion=0.05, politics=0). This is called Topic Modeling.
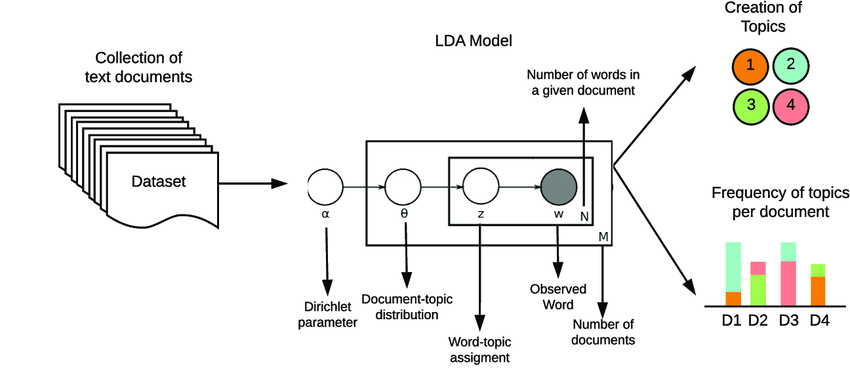
LDA, or Latent Dirichlet Allocation, is not as complicated to understand as your second language might be at first, though. Essentially, it works as such:
Your model, at this stage, is built and ready for input data. Once you have found data you wish to be used for the model to learn, you then describe to your model the various topics that these data points are addressing. (This data could be from Wikipedia articles, news sources, etc.) For example, out of 1,000 articles, there should be maybe 100 topics. This way, articles can be sorted into different categories depending on their content.
Once the model has been trained on these data points, it is ready to learn new input data! Now, if an article is inputted into the model, the LDA will be able to interpret the article and sort it accordingly. The data for every new article sorted will look something like this:
topic#3 is the main topic (0.7)
topic#17 is a secondary topic (0.3)
topic#99 is also in there (0.1)
And so on.
The model will also be able to provide you information, such as the most important keywords or phrases in a given topic. If you ask it for this information, let’s say for an article written about Covid-19, you might ask it: “in topic#3 What are the most important words?” and it might reply: “Pandemic, Coronavirus, Covid, Vaccine, .…”
Out of all of the probable applications or purposes for using the LDA/ Topic Modeling system, the most prevalent use of the model is typically in regards to spam protection. If you were to run your own emails into a spam-based model, the analysis of the emails would be, for example, much like this:
topic#5: free, trial, offer, lottery, limited
topic#7: meeting, urgent, $TIME
And so on.
This type of explanation, much like topics for sorting articles, will categorize emails based on words that are prominent within them. If topic#5 shows up, it’ll be trained to kick those into spam; topic#7 would be marked as important.
Large amounts of our datasets are either github comments and issues, as well as Reddit content. Many of these data points contain information not necessary or relevant to what we want to accomplish. Topic Modeling, in its essence, helps us weed out or choose what we want to keep.
Before training the LDA, some data preprocessing is needed. At least this includes tokenizing and stemming or lemmatizing:
Additional preprocessing steps that we take to improve accuracy, but is not strictly necessary:
Choosing the order to do the above steps can be tricky: some steps need to be applied simultaneously. For this reason, instead of the sequential approach (NLTK) we use a model-based approach (SPACY). This framework is flexible enough for us to add some specific rules for our particular domain.
After the preprocessing, we apply the LDA model. Here is what LDA Modeling allows us to do, in a bit more detail:
LDA assumes that each document consists of a collection of topics that are hidden ("latent") and it tries to find those topics. It does so by finding words that appear together within the same document. The goal is to find a group of topics from which you could generate all the documents in your training set. The end result is having topics defined by the words that appear within them. From this model, we simply feed it a new document and it will find those topics that could have been used to generate that document, and you can do this as many times as needed.
LDA is one of several Topic Modeling algorithms, but it’s most appropriate for our usage. Topic Modeling is a resource that can help developers sort and interpret data in mass quantities. But, like your next Italian lesson, time and some proper correction is needed to really make the model function at its maximum capacity. Maybe you don’t want to learn the Italian for the “politics” topic but you do want it for the “economics” topic; Topic Modeling can be used for screening the articles that you want to read.